Roofline Models: From Speculation to Modelling
Understanding the Machine
A modern Central Processing Unit (CPU) consists of multiple independent execution units called cores. Each core is an independent hardware unit containing its own execution pipeline, registers, and control logic. A multicore CPU with $N$ physical cores can run up to $N$ independent execution streams in parallel.
Unlike physical cores, a thread is a software-defined execution context comprising a program counter, register states, and a call stack. Operating systems schedule threads onto physical cores. A core executes instructions from a single thread context at any given moment, unless it supports Simultaneous Multithreading (SMT).
SMT allows a single physical core to interleave instructions from multiple thread contexts, optimizing pipeline utilization without doubling raw execution hardware.
Parallel Execution
Parallelism arises from simultaneously executing workload(s) on multiple cores.
For $C$ physical cores and $T$ threads:
- If $T \le C$, threads can execute concurrently in parallel.
- If $T > C$, the operating system must time-slice execution.
In C++, multi-threading can be introduced via OpenMP directives or standard std::jthread/std::thread. While standard library threads provide low-level control, OpenMP simplifies thread pooling and work sharing with minimal developer overhead.
SMT allows multiple threads to share a single core, but this is a latency-hiding mechanism rather than a source of linear speedup.
Memory Hierarchy
The processor does not operate directly on data from main memory in most cases. Instead, it relies on a hierarchy:
- Registers (inside the core, fastest)
- L1 / L2 / L3 caches (on-chip, small but fast)
- Main memory (RAM)
- Secondary storage (SSD/HDD)
Data movement becomes progressively slower and more expensive as we go down this hierarchy.
For performance analysis, the critical boundary is between:
- on-chip computation
- off-chip memory (RAM)
Compute vs Data Movement
Any program performs two fundamental actions:
- Compute - arithmetic operations executed by the core
- Data movement - transferring data between memory and the core
Performance is limited by whichever of these becomes the bottleneck.
To quantify this, we define:
- Peak compute throughput: maximum operations per second a CPU can perform
- Memory bandwidth: maximum rate at which data can be transferred from memory
Arithmetic Intensity
Arithmetic intensity (AI) is the ratio of floating-point operations (FLOPs) to memory transfers (bytes) for a given kernel. It quantifies how many times each fetched byte is reused in computation; a higher AI implies more compute work per memory access.
This ratio categorizes kernels into two regimes:
- Low intensity → memory-bound
- High intensity → compute-bound
For example, the STREAM Triad benchmark (
A[i] = B[i] + scalar * C[i]) measures sustainable memory bandwidth. Each iteration performs 2 FLOPs (one multiply, one add) but transfers 3 vectors’ worth of data (two reads, one write), totaling 24 bytes in double-precision. This yields an arithmetic intensity of approximately 0.083 FLOPs/byte, classifying it as a heavily memory-bound kernel.
Toward the Roofline Model
The roofline model was first introduced by a group of scientists at the University of California, Berkeley in 2008, in a paper titled:
Roofline: An Insightful Visual Performance Model for Floating-Point Programs
and Multicore Architectures
By Samuel Williams, Andrew Waterman and David Patterson
The Roofline model combines peak compute throughput, memory bandwidth, and operational intensity to determine the maximum achievable performance of a program on a given machine. It answers two key questions:
- Is the program limited by compute or memory?
- How far is the implementation from hardware limits?
Building a Roofline Model
Constructing a Roofline model requires precise parameters. The accuracy of the model depends on the rigor of these measurements.
- Peak Sustained Memory Bandwidth: Measured using benchmarking suites like STREAM (specifically the Triad kernel). Refer to this implementation for detail.
- Peak Compute Throughput:
- Arithmetic Intensity:
- Arithmetic Intensity Ridge Point:
- The Roofline Bound:
Visualizing a Roofline Model
Here is the roofline model characterising the AMD Ryzen 5 6600H processor.
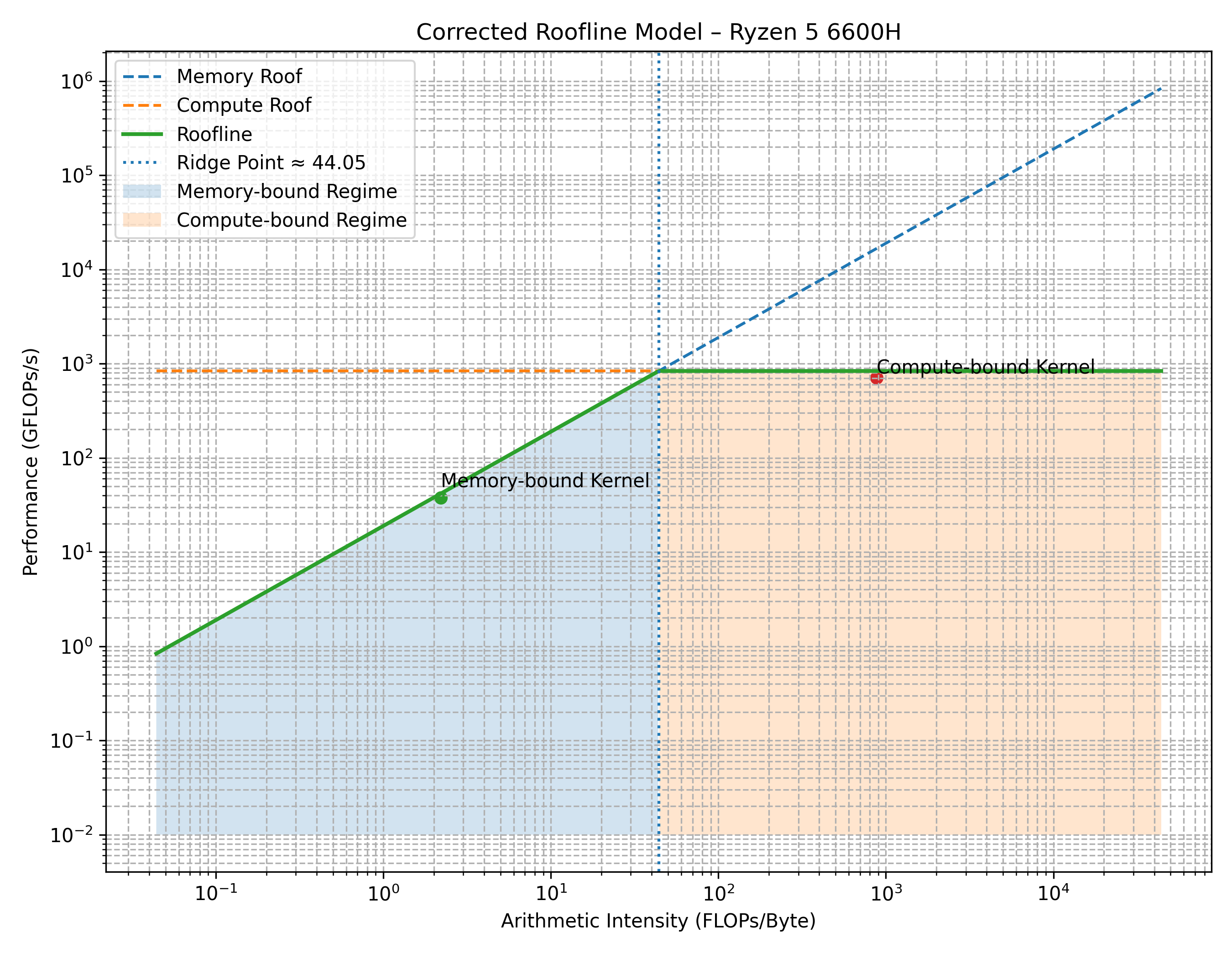
- X-axis: Arithmetic Intensity (log scale).
- Y-axis: Performance in FLOPs/sec (log scale).
Workloads fall into one of two operational regimes:
- Memory-Bound (blue): Performance is limited by and scales with memory bandwidth.
- Compute-Bound (orange): Performance is capped by the peak compute capacity of the execution units.
The upper boundary (plotted in green) represents the peak achievable performance as a function of Arithmetic Intensity (AI). The diagonal line represents the memory-bandwidth limit, and the horizontal ceiling represents the compute limit.
Using the Roofline Model
The Roofline model serves as a diagnostic tool, mapping workloads on a coordinate system to represent their execution behavior. The optimization goal is to increase arithmetic intensity, moving the workload to the right to saturate execution units and extract performance from the hardware.
- For memory-bound workloads: Increasing AI moves performance diagonally up the slope until it hits the compute ceiling.
- For compute-bound workloads: Performance is improved by optimizing execution efficiency (e.g., using SIMD vector instructions or reducing instruction overhead).
Glacier.HPC
Glacier.HPC focuses on profiling, benchmarking, and optimizing numerical kernels on consumer-grade hardware. Derived from the Glacier.ML codebase, this project focuses on:
- Measuring arithmetic intensity and raw performance.
- Constructing empirical Roofline models.
- Evaluating compiler and loop optimization strategies.
These insights are then used to optimize Glacier.ML.
To reference this post with full LaTeX equation formatting, you can view the raw markdown source at GitHub.
This post is based on experimental results from Glacier.HPC. A detailed analysis using the SAXPY kernel will be covered in the next post.