Building SVMs from Scratch in C++: Glacier’s PEGASOS Implementation
Glacier.ML now includes working implementations of:
- SVM Classifier
- SVM Regressor
Both are implemented in C++ using:
- Eigen for linear algebra
- OpenMP for multithreading
- OpenBLAS for optimized BLAS routines
In local benchmarks, the classifier variant demonstrates 4–10× faster training compared to scikit-learn under comparable conditions. This post documents the algorithmic design, performance characteristics, and implementation philosophy behind these models.
Algorithmic Clarification: Not Classical Kernel SVM
Glacier’s SVM implementations are not dual-form, kernelized SVMs. Instead, they are based on:
PEGASOS
(Primal Estimated sub-Gradient Solver for SVM)
PEGASOS directly optimizes the primal objective using stochastic subgradient descent.
Classification Objective
\[\min_{w} \frac{\lambda}{2} \|w\|^2 + \frac{1}{m} \sum_{i=1}^{m} \max\left(0,\; 1 - y_i\, w^{T} x_i\right)\]Regression Objective (ε-insensitive loss)
\[\min_{w} \frac{\lambda}{2} \|w\|^2 + \frac{1}{m} \sum_{i=1}^{m} \max\left(0,\; |y_i - w^{T} x_i| - \epsilon\right)\]Consequently, Glacier’s SVM variants are closer in behavior to linear stochastic gradient descent (SGDClassifier / SGDRegressor) rather than kernelized Support Vector Classifiers (SVC), as no feature mapping or kernel transformations are performed. The models are strictly linear.
Implementation Stack
1. Eigen + OpenBLAS
- Eigen provides matrix abstractions and expression templates.
- OpenBLAS accelerates low-level BLAS operations.
Key goals:
- Cache-friendly layouts
- Minimal heap allocations
- Efficient vectorized dot products
- Reduced abstraction overhead
The codebase avoids redundant temporary objects and prioritizes cache-local updates.
2. OpenMP Threading Strategy
Glacier defaults to using half of the available hardware threads. Limiting thread saturation mitigates thermal throttling, stabilizes sustained performance, and preserves overall system responsiveness. Because scikit-learn’s thread usage varies depending on the underlying BLAS backend, differences in thread policy can significantly impact comparative training times.
Performance Observations
Speed
The classifier model showed 4–10× faster training compared to scikit-learn in local tests.
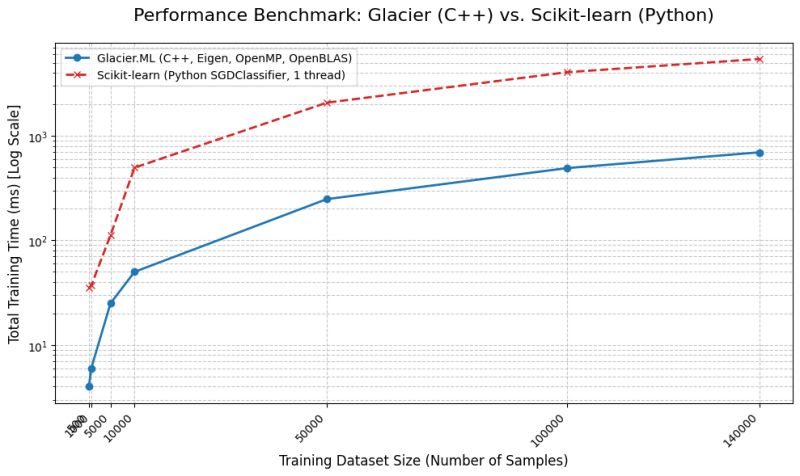
Crucially, these comparisons are not strictly apples-to-apples due to differences in convergence criteria, memory layouts, and learning rate scheduling.
Underfitting on “Give Me Some Credit”
Both implementations underfit on the “Give Me Some Credit” dataset.
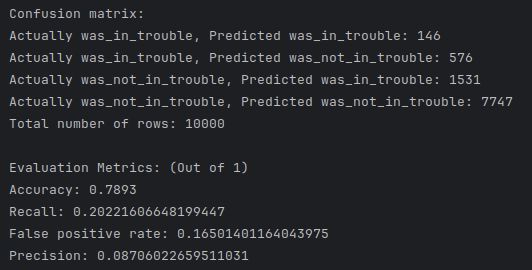
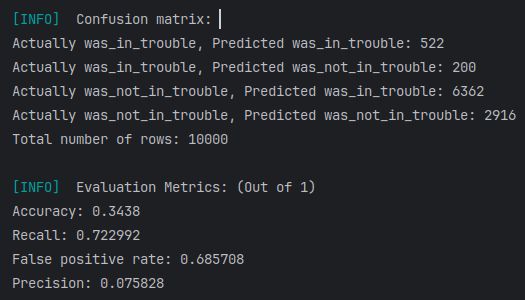
This is evidenced by poor recall on minority classes and overlapping confusion matrices. This occurs because the data requires a non-linear decision surface, which a strictly linear SVM cannot resolve without kernel expansion or feature engineering. This behavior is expected.
Architectural Decisions
Core design choices:
- Use primal optimization (PEGASOS)
- Avoid kernel complexity at this stage
- Emphasize hardware-level control
- Optimize CPU usage consciously
- Maintain explicit control over memory and threading
The codebase is not a direct transcription of any single reference; it is the result of iterative derivation, benchmarking, and refinement.
Learning with AI vs. Copying from AI
Mathematical derivations and implementation details were developed with the assistance of AI tools. The distinction between learning and copying lies in the ability to re-derive the objective function, implement the solver from scratch, and understand convergence behavior, regularization, and hardware trade-offs. Re-implementing a library from first principles guarantees conceptual ownership and clarity.
AI tools functioned as a refinement engine, error detector, and a resource to accelerate textbook research, while the core architectural decisions remained strictly manual.
Systems-Level Insights
Implementing PEGASOS from scratch highlights systems-level challenges like memory bandwidth limits, thread synchronization, numerical stability in subgradient descent, and learning rate scheduling. The exercise bridges algorithmic theory with hardware-aware optimization.
Future Scope
The next structural milestone is CUDA acceleration. This will enable:
- Large-scale mini-batch updates
- Faster convergence on high-dimensional datasets
- Experimental work in GPU-accelerated optimization
This work is planned for subsequent iterations.
Conclusion
Glacier’s SVM implementations leverage the PEGASOS primal optimization method in C++, integrating Eigen, OpenMP, and OpenBLAS to achieve high training speeds. They underfit predictably on non-linear datasets, reflecting expected theoretical limits.
The primary value of Glacier lies in establishing vertical control—bridging mathematical theory, memory layout, thread scheduling, and machine execution. This foundational understanding compounds.