Optimized k Nearest Neighbours: From Naive to Hardware-Aware
k-Nearest Neighbors (kNN) is a fundamental supervised machine learning algorithm. As a lazy learner, the kNN kernel performs all computation during inference rather than requiring an explicit training phase.
This work shows that, when optimized systematically across mathematical, software, and hardware dimensions, kNN execution speed can be pushed closer to hardware limits, without modifying the underlying algorithm or target CPU.
By following a structured optimization path, the kNN Classifier and Regressor implementations achieve
up to a 250x speedup over the naive baseline.
A Structured Path to Performance
The optimization followed a clear and layered progression:
- Naive implementation of the mathematical model
- Mathematical optimizations of the same model
- Software-centric optimizations
- Hardware-centric optimizations
Each layer presented their own bottlenecks and opportunities.
Mathematical optimizations
Efficient Selection of Neighbors
A significant portion of inference time is spent searching for the $k$ nearest neighbors. While a
naive approach sorts or uses a std::priority_queue to retrieve the top elements, a more computationally efficient
alternative uses std::nth_element to partition the vector in $O(N)$ average time.
Software-centric optimizations
Efficient Data Layout
- Contiguous Row-Major Representation: The 2D feature matrix, originally represented as nested vectors (
std::vector<std::vector<float>>), was flattened into a contiguous 1Dstd::vector<float>using the mapping:X[row * num_cols + col]This flat layout offers:
- Reduced cache misses due to spatial locality.
- Predictable strided memory access.
- Enablement of compiler auto-vectorization (SIMD) on the contiguous memory block.
Hardware-centric optimizations
Parallelization using OpenMP
- Multithreading enables concurrent execution across CPU cores, reducing overall execution time despite minor synchronization overhead. Using OpenMP, this parallelization is enabled at compile time with the
-fopenmpflag. - On an AMD Ryzen 5 6600H CPU (6 cores, 12 threads), allocating half of the available hardware threads (6 threads) yielded the highest efficiency by avoiding hyperthreading overhead and thread contention.
SIMD Vectorization
- Distance computation relies heavily on sum reductions. Compiling with
-march=nativeallows the compiler to leverage SIMD vector extensions (such as AVX2 or AVX-512) for automated reduction vectorization.
Compiler Flag Optimizations
- Switching from
-O0to-O3enables aggressive compiler optimizations. -ffast-mathpermits additional optimizations (like reassociating floating-point operations) at the expense of strict IEEE 754 compliance, speeding up computations at the cost of strict numerical precision.
Profiling
- The
perfutility was used to profile the executable and identify hot spots in the execution path.
Results
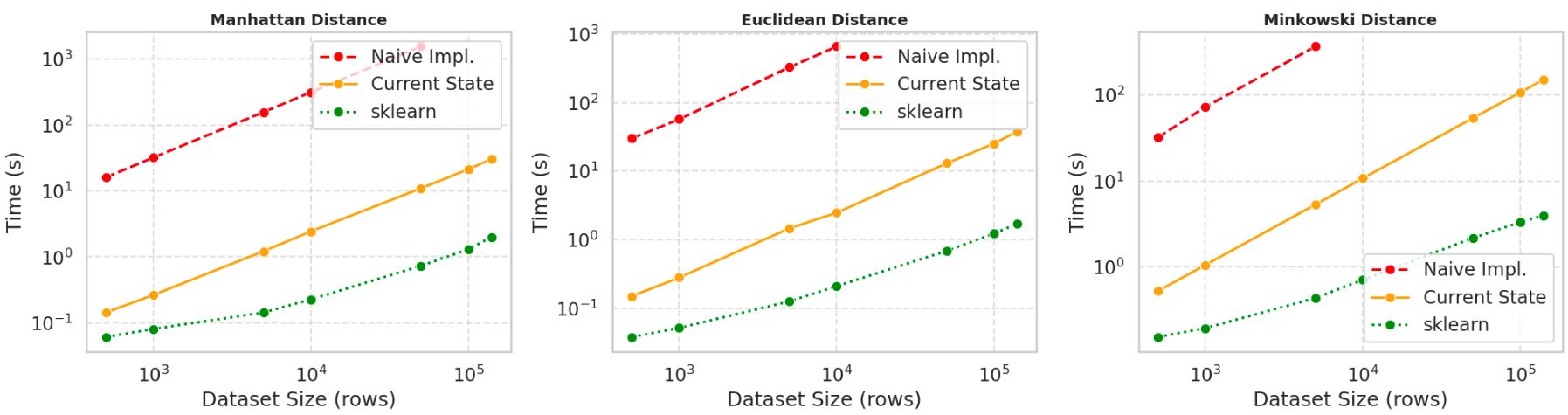
- Datasets ranged in size from $500 \times 10$ to $140,000 \times 10$.
- The optimized implementation achieved a $100\times$ to $250\times$ speedup compared to unoptimized baseline builds.
- The optimized implementation remains $4\times$ to $36\times$ slower than scikit-learn’s implementation under identical hyperparameters, demonstrating the sophistication of production-grade libraries.
- The optimization infrastructure introduced additional code complexity and increased compile times.
Benchmarking Setup
- Hardware: AMD Ryzen 5 6600H CPU, 8GB RAM.
- Environment: All manual background processes were closed, and the machine was set to performance power mode on AC power.
Key Learnings
- A clear distinction exists between a mathematical model on paper, a direct code translation, and a hardware-aware, optimized implementation.
- Understanding operating system scheduling and CPU cache hierarchies is critical for systems programming.
- Profiling tools (like
perf) and integrated environments are essential for identifying micro-architectural bottlenecks. - High-level libraries and wrappers abstract away significant underlying systems-engineering complexity.