Optimized k Nearest Neighbours: From Naive to Hardware-Aware
KNN is one of the simplest Supervised ML algorithms to be taught to ML aspirants. Being a lazy learner, the KNN kernel is only used during prediction not to train the model.
This work shows that, when approached systematically across mathematical, software and hardware dimensions, KNN can be pushed closer to the hardware limits, while retaining the underlying algorithm and hardware.
By following a structured optimization path, the KNN Classifier and Regressor implementations achieve
upto 250x speed-up over naive baseline.
A Structured Path to Performance
The optimization followed a clear and layered progression:
- Naive implementation of the mathematical model
- Mathematical optimizations of the same model
- Software-centric optimizations
- Hardware-centric optimizations
Each layer presented their own bottlenecks and opportunities.
Mathematical optimizations
Efficient Selection of Neighbours
A significant computation is taken up in searching the k nearest neighbours from the query. While
the naive approach involves using a min_heap to arrange and retrive the points, a much cost effective
alternative involves using std::nth_element for the same.
Software-centric optimizations
Efficient Data Layout optimization
- Row major / Column major representation: Originally, the 2 dimensional X matrix was
represented using
std::vector<std::vector<float>>. It was then replaced withstd::vector<float>.Transformation: X[row, col] => X[row * Ncols + col]This results in:
- Lower cache misses
- Predictable stride, resulting in predictable memory access
- Enables SIMD auto-vectorization by the compiler, given the matrix is densely populated.
Hardware-centric optimizations
Parallelization using OpenMP:
- Parallelization allows multiple threads in the CPU to carry out operations parallely, resulting in
lowered time consumption at the cost of added synchronization overhead.
OpenMPenables parallelization on supported CPUs when used with the flag-fopenmpused during compilation. - When used on a CPU with all cores of equal performance and 2 threads for each core, using half the total available threads (6/12 threads) resulted in the best performance.
SIMD Vectorization:
- Distance computation results in repeated summations, enabling
reductions. Using-march=nativeallows AVX512/AVX2 auto-reductions based on the chip architecture.
Compiler Flag Optimizations
- Switched from using
-O0to-O3enabling aggressive hardware specific optimization. -ffast-mathallows faster math operations while compromising on mathematical stability.
Profiling
perfwas used to profile the code and identify high runtime hotspots.
Result
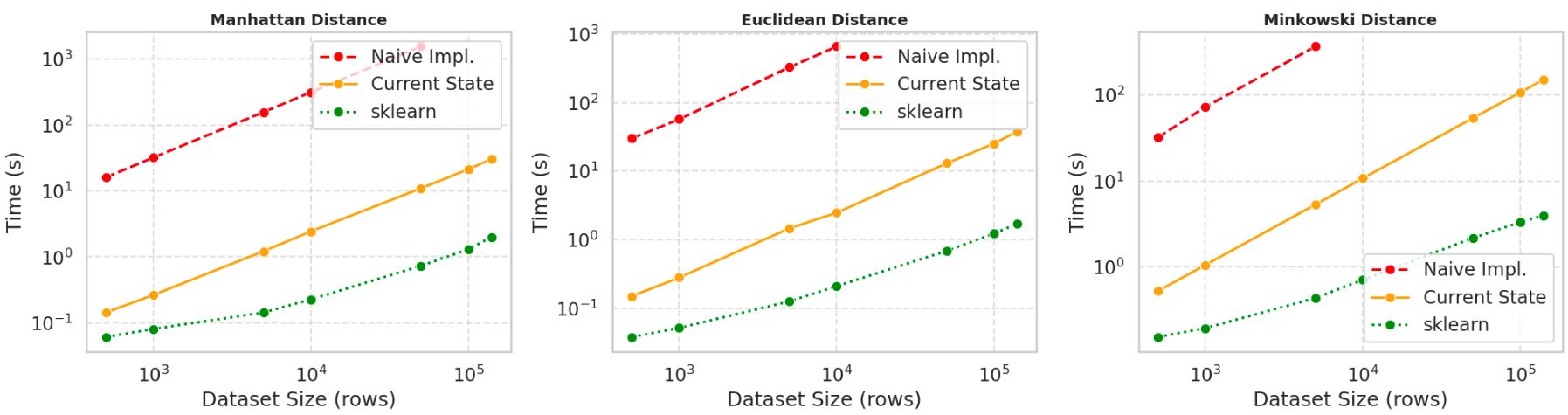
Benchmarking Setup
- Datasets ranged from 500x10 to 140,000x10.
- Observed 100x to 250x speed-up compared to unoptimized builds.
- Final implementation still 4x to 36x slower than scikit-learn models when used with same hyperparameters.
- Optimization infrastructure increased the code complexity and compile time.
Learnings
- Clear distinction between:
- Mathematical models on paper
- Mathematical implementations using code
- hardware-aware optimized models
- Importance of understanding
- Operating systems
- CPU architecture
- Importance of
- Profiling tools like
perf - Robust IDEs like CLion
- Profiling tools like
- Realization that high-level bindings and wrappers hide extensive engineering effort.