Building my own C++20 Numerical Algorithms library
Glacier.ML is a header-only numerical algorithms library implemented entirely in C++ with Eigen sometimes used for linear algebra.
 The project originated as a follow-up to formal coursework in multivariate statistical modeling, specifically linear regression and its evaluation metrics. To translate theory into implementation, I used Stanford Online’s Statistical Learning lectures as a mathematical reference, while avoiding existing ML frameworks.
The project originated as a follow-up to formal coursework in multivariate statistical modeling, specifically linear regression and its evaluation metrics. To translate theory into implementation, I used Stanford Online’s Statistical Learning lectures as a mathematical reference, while avoiding existing ML frameworks.
A primitive prototype was reviewed by my AI professor, whose feedback shifted the project from experimentation to sustained development.
At present, Glacier.ML implements three stable models:
- Simple Linear Regression
- Multiple Linear Regression
- Binary Logistic Regression
The logistic regression implementation has been trained, tested, and validated on two real-world datasets:
- Pima Indians Diabetes Dataset (768 × 9)
- Wisconsin Diagnostic Breast Cancer Dataset (569 × 32)
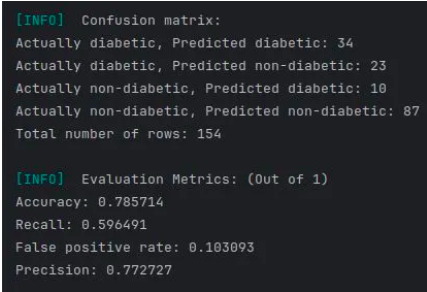
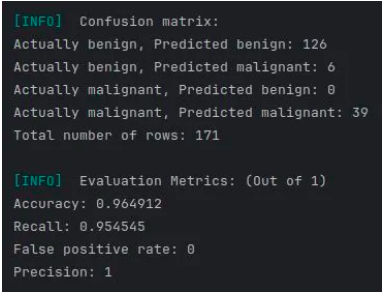 Confusion matrices for the datasets Pima Indians Diabetes Database and Wisconsin Cancer Diagnostic Dataset respectively
Press enter or click to view image in full size
Confusion matrices for the datasets Pima Indians Diabetes Database and Wisconsin Cancer Diagnostic Dataset respectively
Press enter or click to view image in full size
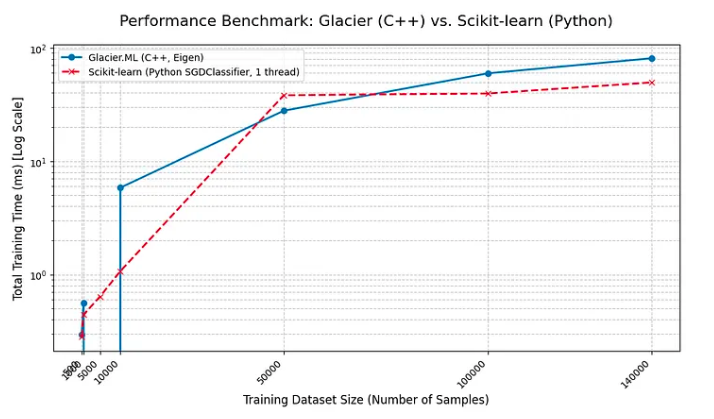 Benchmarking training time of Glacier’s Logistic Regression against Scikit-learn’s Logistic Regression
Evaluation metrics and training-time comparisons were measured against Scikit-learn’s logistic regression. Despite lacking explicit optimization and parallelism, the results were comparable in both accuracy and training time.
Benchmarking training time of Glacier’s Logistic Regression against Scikit-learn’s Logistic Regression
Evaluation metrics and training-time comparisons were measured against Scikit-learn’s logistic regression. Despite lacking explicit optimization and parallelism, the results were comparable in both accuracy and training time.
This project exposed low-level numerical issues rarely encountered in higher-level ML workflows, including floating-point underflow and stability constraints.
Below is a minimal example demonstrating dataset ingestion, training, prediction, and evaluation using Glacier.ML’s binary logistic regression pipeline.
#include "Glacier/Models/MLmodel.hpp"
#include "Glacier/Utils/utilities.hpp"
int main() {
std::vector<std::vector<float>> X, X_t;
std::vector<std::string> y, y_t;
Glacier::Utils::read_csv_c("../Datasets/training_dataset.csv", X, y, true);
Glacier::Utils::read_csv_c("../Datasets/testing_dataset.csv", X_t, y_t, true);
std::vector<std::vector<float>> X_p = {
{1, 2, 3 .... n}
};
std::vector<std::string> y_p = {"label_1"};
Glacier::Models::MLmodel md(X, y);
float hp1 = 1.0f;
md.train(hp1);
auto md_pred = md.predict(X_p);
md.analyze_2_targets(X_t, y_t);
return 0;
}
This example illustrates Glacier.ML’s design goal: a minimal, explicit training and evaluation pipeline without hidden abstractions. Hyperparameters, data ingestion, and evaluation remain directly visible to the user.
Link to the project’s GitHub repository:
GitHub - https://github.com/skandanyal/Glacier.ML